
Part of the work was to consider not just the technology but the experience of a LLM being instructed to create a poem. I mean..that's kinda crazy — or it was. This goes back to when Near Future Laboratory first started exploring the possibilities of AI and LLMs and learning the various APIs and how to use them. So, at first, instructing an LLM to emanate a poem was pretty friggin' weird/magical/alchemical. But now? Well, now it's just table stakes, if even that. And then even trying to assess the quality and character of the poem and its ability to create meaning and feeling — that's almost eclipsed by the fact that a machine can some how do it.
I suppose its trite to say that the jury is still out on whether or not this is a good thing, but empirically? It's a thing for sure. And it will likely be a thing that is going to be a part of our lives in some way, shape or form. So, I guess the question is — how do we want to live with it? How do we want to use it? How do we want to make it a part of our lives? And what does that mean for us as humans? As people who create and share and experience things? That's the real question, isn't it?
Parenthetical to this I was thinking about how this is some how in conversation (in the metaphorical sense, because I cannot get his attention) with the work that Matt is doing with his [Poem/1](https://arstechnica.com/information-technology/2024/01/rhyming-ai-powered-clock-sometimes-lies-about-the-time-makes-up-words/) project. I backed that horse some time ago, but not much news. I appreciated the spirit and effort to make a (very typically) twee object that would sit on a twee shelf and emanate poems. But now? That seems less interesting. I mean..it's going to sit there and emanate machine poetry. Is that exciting as a thing, or is that just “a thing”? I mean, I guess it is a thing. But is it a thing that we want to have in our lives? Is it a thing that we want to share with others? Is it a thing that we want to be a part of our lives? Or is it just a thing that we can have and then forget about? I don't know. I guess that's the question, isn't it?
Also, hardware? It occured to me, as much as I like to make a thing that it could have been a richer story if it was built into hardware that already exists that is often otherwise thrown away — like an old iOS device or some such. I have to imagine that now, at this moment, given that I believe Matt was doing this in China, that there are more pressing issues to getting the project done. You know..tariffs and such.
This is what the Poem Operating System robot I made with OpenAI and Eleven Labs has been creating 👆🏽
Someone somewhere in the NFL Discord during a recent Office Hours perhaps it was, mentioned a world in which an Operating System was somehow a Poem-based OS.
So I guess, thinking about Poem/1 and such — somehow the idiom of Poetry has been with me for, well — that’s 20 years, eh? I think that’s partially because you can get away with non-sense or things that are not immediately valuable for their utility. Like — people don’t wardrive for the sake of making poetry, they usually do it to find open access points and then exploit them for nefarious who-knows-what-but-you-might-guess. If someone wardrove and said they were a War Driving Poet, you might at one level be, like..oh, okay. But…why?
So now here I am wandering into wondering about a Poem OS so I asked ChatGPT to assume I had an OpenAI API key (which I do) and an Elevenlabs API key (which I do) and gave it some speciifications.
How about a Python program that interfaces with the Open AI API and with the ElevenLabs API that generates a short pithy poem and then generates audio of that poem read by an ElevenLabs voice. Assume I have API keys for both of these services.
I’d like to be able to provide the specific prompt to generate the poem in a configuration file as an array of possible prompts for each day of the week, and assume one poem is generated per day.
I got this back amongst some other stuff, that didn’t quite work but was enough of a simple scaffolding that I could then start to fix and refine it.
import jsonimport openaiimport requestsfrom datetime import datetime
# Load your API keys from an environment variable or a secure fileopenai_api_key = "your_openai_api_key"elevenlabs_api_key = "your_elevenlabs_api_key"
# Configure your OpenAI and ElevenLabs API keysopenai.api_key = openai_api_key
# Load prompts from the configuration filewith open("config.json", "r") as file: prompts = json.load(file)
# Determine today's day and select a prompttoday = datetime.now().strftime("%A")prompt = prompts[today][0] # Choosing the first prompt for simplicity
# Generate a poem using OpenAI's APIresponse = openai.Completion.create( engine="text-davinci-003", prompt=f"Write a short, pithy poem about {prompt}.", max_tokens=100, temperature=0.7)
poem = response.choices[0].text.strip()print("Generated Poem:\n", poem)
# Generate audio of the poem using ElevenLabs APIelevenlabs_url = "https://api.elevenlabs.io/synthesize"elevenlabs_headers = {"Authorization": f"Bearer {elevenlabs_api_key}"}elevenlabs_data = { "text": poem, "voice": "selected_voice_id" # You need to select a voice ID from ElevenLabs' list}
audio_response = requests.post(elevenlabs_url, json=elevenlabs_data, headers=elevenlabs_headers)
if audio_response.ok: # Save the audio file. The exact method depends on ElevenLabs' response format with open("poem_audio.mp3", "wb") as audio_file: audio_file.write(audio_response.content) print("Audio generated successfully.")else: print("Failed to generate audio.")Less than an hour or so of tweaking the initial response from ChatGPT — which was a great start but not quite there and had some API interfacing entirely wrong — I started effectively evolving, reconsidering, and refining what I wanted PoemOS thing to do. I’m thinking — okay, different kind of Poem for each day of the week, just focusing on the day of the week.
And now I’m thinking..what about a version that listens to action in the Near Future Laboratory Discord community and makes a poem about that, or the kind of low-hanging-fruit edition that does a News Poem based on what happened that day or the day before — or a weekly summary as a Poem. I bet that’d be kinda weird?
So now I’m imagining what I would do with an mp3 file of something/some voice reading a poem that something else made.
But, sitting there in the studio and listening to the reading voice reading a machine generated Poem didn’t feel done or complete.
So I drop that audio file into Descript, which is one hammer in the toolbox I use to produce the Near Future Laboratory Podcast so now I have a transcript and can use Descript’s very awkward side tool to create one of those audiograms that basically strums out the libretto/text/transcript or whatever you’d call it for the generated audio. So now I have a poem, being read, with the words playing out in a video.
And now I’m taking this video and I drop it into Davinci Resolve Studio Edition, and stir in some graphics and some background video I shot the other day, and now I have a little video poem.
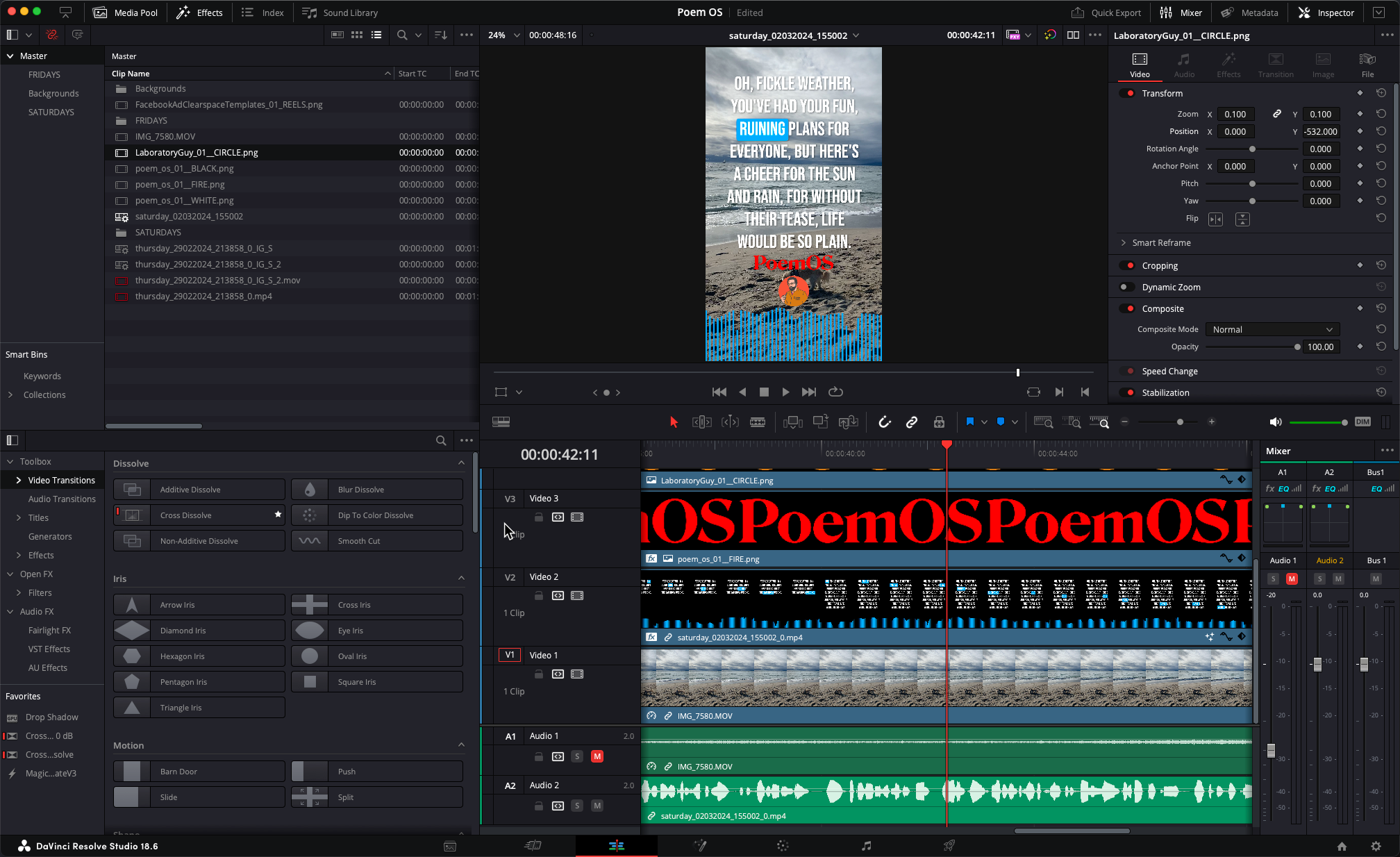
So — this was just a couple hour Thursday evening experiment, the day after a pretty focussed and intense day at Chapman University when I wanted to do something that just felt like something where no one was necessarily expecting anything.
A study of an artifact from a future in which you get a Poem popped up into your audioscape.
Next steps? Well — there are so many adjacent possibilities that I’ll reserve new ideas for another one of those kinds of wandering days looking for different kinds of possible futures.
Here’s the Github repo, if you’re curious: https://github.com/NearFutureLaboratory/poem_os
And this is the evolution with me banging away on the keyboard to imagine in code and wandering around half-baked ideas about what I was doing about 45 minutes after what ChatGPT initially suggested 👇🏽
import json# import openaiimport requestsfrom datetime import datetimefrom openai import OpenAIfrom pydub import AudioSegmentfrom pydub.playback import playimport os
def create_poem(prompt):
response = client.chat.completions.create( messages=[ { "role": "user", "content": prompt, } ], model="gpt-4-turbo-preview", )
result = response.choices[0].message.content.strip() return result
def get_all_voices():
# An API key is defined here. You'd normally get this from the service you're accessing. It's a form of authentication. XI_API_KEY = elevenlabs_api_key
# This is the URL for the API endpoint we'll be making a GET request to. url = "https://api.elevenlabs.io/v1/voices"
# Here, headers for the HTTP request are being set up. # Headers provide metadata about the request. In this case, we're specifying the content type and including our API key for authentication. headers = { "Accept": "application/json", "xi-api-key": elevenlabs_api_key, "Content-Type": "application/json" }
# A GET request is sent to the API endpoint. The URL and the headers are passed into the request. response = requests.get(url, headers=headers)
# The JSON response from the API is parsed using the built-in .json() method from the 'requests' library. # This transforms the JSON data into a Python dictionary for further processing. # I want to keep a list of the current voices I have available. data = response.json() with open('./voices.json', 'w') as json_file: json.dump(data, json_file, indent=4) # A loop is created to iterate over each 'voice' in the 'voices' list from the parsed data. # The 'voices' list consists of dictionaries, each representing a unique voice provided by the API. for voice in data['voices']: # For each 'voice', the 'name' and 'voice_id' are printed out. # These keys in the voice dictionary contain values that provide information about the specific voice. print(f"{voice['name']}; {voice['voice_id']}")
return data['voices']# Load configuration, API keys, and prompts from the configuration file
with open("config.json", "r") as file: config = json.load(file)
openai_api_key = config["api_keys"]["openai"]elevenlabs_api_key = config["api_keys"]["elevenlabs"]
with open("prompts.json", "r") as file: p = json.load(file)
prompts = p["prompts"]
# Configure your OpenAI API keyOpenAI.api_key = openai_api_keyclient = OpenAI( api_key=OpenAI.api_key,)
voices = get_all_voices()
# Determine today's day and select a prompttoday = datetime.now().strftime("%A")prompt = prompts[today]["prompts"][0]# Choosing the first prompt for simplicity
poem = create_poem(prompt)
print("Generated Poem:\n", poem)
CHUNK_SIZE = 1024voice_id = prompts[today]["voice_id"]
# Generate audio of the poem using ElevenLabs APIelevenlabs_url = f"https://api.elevenlabs.io/v1/text-to-speech/{voice_id}"print(elevenlabs_url)
data = { "text": f"{poem}", "model_id": "eleven_monolingual_v1", "voice_settings": { "stability": 0.5, "similarity_boost": 0.5 }}
headers = { "Accept": "audio/mpeg", "Content-Type": "application/json", "xi-api-key": elevenlabs_api_key}
response = requests.post(elevenlabs_url, json=data, headers=headers)if response.status_code != 200: print(f"Failed to generate audio. Status code: {audio_response.status_code}")else:# Assuming `prompt` is the selected prompt for today today_date = datetime.now().strftime("%d%m%Y") today_day = datetime.now().strftime("%A").lower() right_now = datetime.now().strftime("%H%M%S") prompt_index = prompts[today]["prompts"].index(prompt) # Assuming `prompts[today]` returns the list of prompts for today
directory = today_day if not os.path.exists(directory): os.makedirs(directory)
# Format the filename filename_root = f"{today_day}_{today_date}_{right_now}_{prompt_index}" filename_audio = f"{today_day}_{today_date}_{right_now}_{prompt_index}.mp3" filename_path = f"{directory}/{filename_audio}" with open(filename_path, 'wb') as f: for chunk in response.iter_content(chunk_size=CHUNK_SIZE): if chunk: f.write(chunk)
target_voice_id = voice_id voice_name = '' # Find the voice with the specified voice_id for voice in voices: try: print(voice) voice_id = voice['voice_id'] print(voice_id) if voice_id == target_voice_id: voice_name = voice['name'] print(voice_name) break except TypeError as e: print(f"Error: {e}, with element: {voice}")
audio = AudioSegment.from_mp3(filename_path) duration_seconds = len(audio) / 1000.0 # Pydub uses milliseconds
# try to make a compact version if it goes long? could be cartoon-y, but.. target_duration = 59 # Target duration in seconds timed_filename = filename_root if duration_seconds > target_duration: speed_up_factor = duration_seconds / target_duration # Speed up the audio audio = audio.speedup(playback_speed=speed_up_factor) # To save the modified audio timed_filename_path = f"{directory}/{filename_root}_59.mp3" timed_filename_actual = f"{filename_root}_59.mp3" audio.export(timed_filename_path, format="mp3")
# Collect the data to save in a JSON file as a kind of record of what happened poem_data = { "day": today_day, "prompt": prompt, "poem": poem, "voice_name": voice_name, "voice_id": voice_id, "date": today_date, "audio": {"filename" : filename_audio, "duration" : duration_seconds, "timed_filename" : timed_filename} }
# Determine the JSON filename (replace .mp3 with .json in the audio filename) json_filename = filename_audio.replace('.mp3', '.json')
# Save to JSON file with open(json_filename, 'w') as json_file: json.dump(poem_data, json_file, indent=4)
print(f"Data saved to {json_filename}.")And this is an example of the JSON file containing weekday prompts. I go in here and adjust these routinely. I don’t want this to be some 100% automated robot. That’s somehow less interesting than it being more of a wind-up toy that you have to, you know — wind up, clean, adjust, set on a path rather than some daemon that just runs in the background.
{"prompts": { "Sunday": { "prompts": ["Write a short pithy humorous poem about Sunday", "Please write a lymric about Sunday"], "voice_id": "xxx" }, "Monday": { "prompts": ["Please write a knock-knock joke about Monday", "Please write a satirical poem about Monday"], "voice_id": "xxx" }, "Tuesday": { "prompts": ["Write a short pithy humorous poem about Tuesday", "Please write a lymric about Tuesday"], "voice_id": "xxx" }, "Wednesday": { "prompts": ["Please write a knock-knock joke about Wednesday", "Please write a satirical poem about Wednesday"], "voice_id": "xxx" }, "Thursday": { "prompts": ["Write a humorous poem for Thursday", "Please write a lymric about Thursday"], "voice_id": "xxx" }, "Friday": { "prompts": ["Please write a humorous poem for Friday anticipating a weekend of fun that can be read in 60 seconds!", "Please write a satirical poem about Friday"], "voice_id": "xxx" }, "Saturday": { "prompts": ["Please write a knock-knock joke about Saturday", "Please write a satirical poem about Saturday"], "voice_id": "xxx" } }}That’s it. A playful prototype amongst poetry, python, programming and play. I hope you enjoy it. And if you do, please let me know. And if you respect the value of prototyping in this fashion, and you’re looking for help with your own commercial projects — I’m always looking for interesting projects and engagements with commercial partners. So, please reach out if you think we might be able to work together.